

In the last article I mentioned that I was briefly pivoting to cutscene creation and implementation. The plan was to ape the style of the old pre-mission cutscenes from StarCraft, which were glorified interstellar Zoom calls.
The scripts for the cutscenes will be entirely handmade, many of which have already been written and published on this site, at least in rough form. That decision was obvious, but I still needed to decide if I was using human voices/actors to read the lines, or machine created voices. If the latter, I need to figure out if the cutscenes will be fully rendered outside of the game, or procedurally created inside the game.
Much of good voice acting is proper inflection and timing, and I trust neither machine learning nor traditional software to create voices that are nearly as good as a real person. However, procedurally created voices let me create simple cutscenes far quicker, and many of these cutscenes have (fake) celebrity guests with distinct voices.
Ultimately, that means using neural net/AI software. I’ve aimed more than my fair share of criticism towards those products and their bullshit creators. As if to prove me right, I took a five minute break from writing this article to look up the 5k world record, and got the following result.

No, the indoor 5k record is not 12.09, it’s 12.44.09.
Regardless, the voice creation/imitation appears to be the strongest part of the neural nets. For example, check out this ridiculous satire that someone made, where they got an AI Juden Peterstein to say “up yours, woke moralists, we’ll see who cancels who”.
Hold on. Jaime’s now telling me that actually was Jordan Peterson. This is what I had in mind.
Two summers ago I downloaded a bunch of audio clips from POL and stitched them together to make two different videos.
Honestly, until I dug those up I’d forgotten how great they were. Hearing Joe Biden’s voice reading the “you will never be a real woman,” copypasta is great. Same for Andrew Tate taking it in the ass.
The necessity of using third party software to create the voices makes in-game cutscene creation a non-starter. That would have been the ideal solution for two reasons. First, the cutscenes could remain as plain text, which would drastically lower the size of the executable. Second, I need to eventually do a bit of programming anyway to implement things like moving character portraits depending on the speaker. If I’m not generating the cutscene I’ll have to manually provide hints/notes to the program I write that chooses which character portrait animates, and other little things of that nature.
Anyway, graphics aside, it’s not particularly difficult to create a video with computer generated voices. In fact, someone already did this for one of the oldest articles on this site. I tried embedding it below, but since BitChute doesn’t always embed properly, you can find the link here.
But that was using the default Microsoft Sam-tier voices. I want impersonations, so I tried ElevenLabs, which either has the best reputation, or just the best marketing. Whatever the result, it was $50 for a whole year, so I can’t be too mad.
If nothing else, it’s funny to hear the default voice, which is some combination of LA valley girl and corporate ASMR talk about nuking Africa. However, it’s no substitute for the real deal.
Before we go any further, while I’m happy that Eleven Labs doesn’t auto censor the output, they do disable a few of the features if they detect a violation of their “hate policies.” The first time this happened I got a stern message. After that, they just gave me this popup.
Luckily, the “advanced features” that are disabled are worthless anyway, amounting to little more than speculatively inserting emotions into the speech. This definitely doesn’t work for satire, and I’m skeptical that it works for anything.

However, I have to admit I’m blown away by how well they can imitate voices and intonations with just a ~5 minute edited monologue from the character in question. It really does sound like Steven Crowder.
But perhaps they just got lucky with Crowder. Let’s see how well the AI imitates our favourite pill addicted Kermit the frog impersonator.
Probably the best content I’ve made using Mr. Peterstein thus far was accidental, when I forgot to tag the second speaker, and accidentally got him to interview himself. Somehow it works, and even though I included only one prompt for the audience to laugh, the AI took ran with it and inserted additional chuckles in most of the right places.
Unfortunately, it was this moment when ElevenLabs decided to follow along in the footsteps of all other “AI” creation software and shit all over itself in a myriad of ways. First of all, their own user tutorial on creating multi-speaker dialogue just flat out doesn’t work, implying that they have yet to implement the auto-recognize feature that they tout. Secondly, the tutorials I found online do work, but produce such poor quality that it’s worthless.
The tutorials recommend using their “Studio” product, and selecting the “start from scratch” feature. However, basic feature are broken. For example, I couldn’t stop the characters from speaking the tags out loud. Yes, I was following their own tutorial on this, but even they essentially throw their hands up and admit that the software just breaks every now and then.
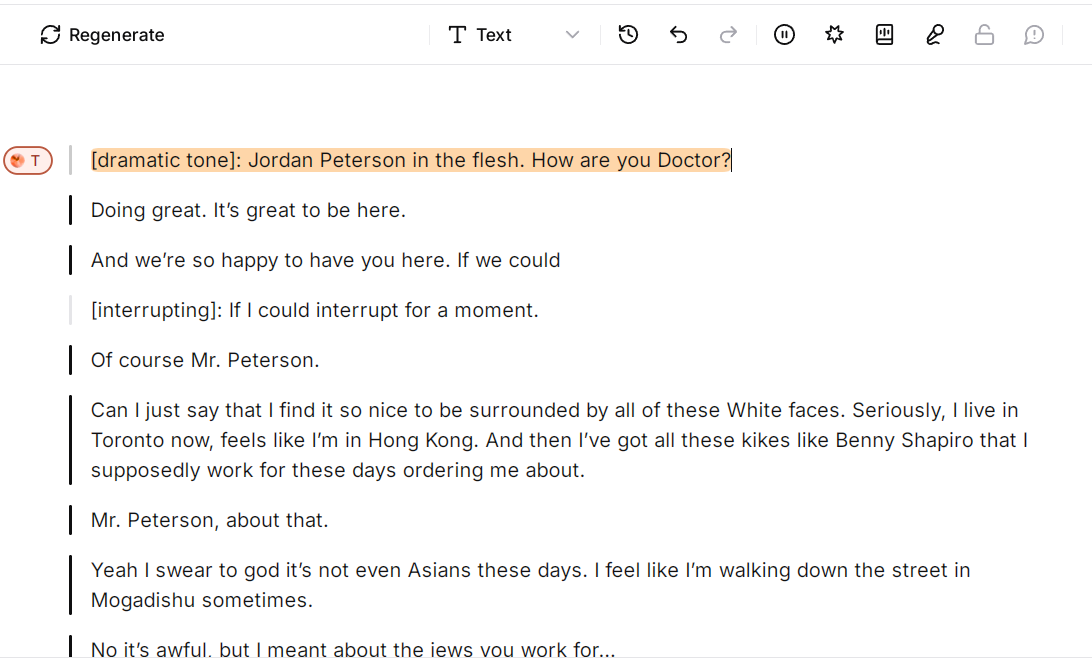
Peterson and myself (AI voices) kept reading the damn emotional prompts/tags.
Another big problem is my AI voice. It’s too loud, and of low quality due to the $10 mic I recorded on. It’s also obvious that I recorded with the mic near my mouth, which makes for a fairly unpleasant listening experience. I might have to splurge for some better recordings of myself, but I’m thinking that I’ll hop on down to a local recording studio and spend an hour of my time saying semi-random things so that I have a good copy of my voice. Apparently it costs only about $60 to rent one of these things out for an hour, and it sounds like a cool experience.
Anyway, I wanted to show you how bad the first attempt at an interview between my AI voice and Jordan Peterson’s AI voice was, but another quirk of that “build from scratch” feature is that you can only download the audio paragraph by paragraph. I have zero idea why this is, but it’s way too much work for me to download a thousand individual lines and then edit them together, just to show a failed creation.

For the record, ElevenLabs got worse and worse the more I used it. I was so impressed the first time, but that was the only time when the prompts, which it understands enough to auto-bold, were properly acted upon. After that, the speakers would read the prompt out loud, even though about half the time there was also an effect inserted simulating the audience reacting appropriately.
I didn’t want you to have to imagine this, so I generated the entire interview using only my AI voice. First of all, in two spots random gibberish is spoken for no apparent reason. Halfway through the video my fake voice changes, and I appear to get a subtle accent. The emphasis is almost never on the correct syllable. Bizarre pauses are hot, heavy, and start almost immediately. And of course, all the prompts are read out loud.
Still, I remain far more impressed by this than the image generation stuff. Imitating someone’s voice is impressive, and it doesn’t need to be perfect for my uses. Comedy requires timing above all else, and while that is mostly ruined in the raw output, I’m perfectly willing to spend an hour or two per cutscene editing it together properly.
I’m going to keep hammering away at this all of Saturday and see what I can come up with.













If somebody wanted to do an AI project (I find that I lack the patience to deal with this stuff, I don’t know how you do it):
Take this video: https://www.youtube.com/watch?v=u9Dg-g7t2l4 [Disturbed’s Sound of Silence cover]
and swap in these lyrics, or something similar:
[Verse 1]
Hello, darkness, my old friend
I’ve come to talk with you again
Because a vision softly creeping
Left its seeds while I was sleeping
And the vision that was planted in my brain
Still remains
Within the sound of sirens
[Verse 2]
In restless dreams, I walked alone
Narrow streets of cobblestone
‘Neath the halo of a street lamp
I turned my collar to the cold and damp
When my eyes were stabbed by the flash of a missile strike
That split the night
And touched off the sound of sirens
[Verse 3]
And in the naked light, I saw
Ten thousand jews, maybe more
Jews kvetching without speaking
Jews scheming without profiting
Jews thinking lies their voices never shared
And no one dared
Disturb the sound of sirens
[Verse 4]
Fools, said I, You do not know
Sirens, like jew cancer grows
Hear my words that I might teach you
Take my arms that I might reach you
But the bombs, like giant raindrops, fell
And echoed in the wails of sirens
[Verse 5]
And the jews bowed and prayed
To the media god they had made
And the screen flashed out its warning
In the words that it was forming
And the screen said, The blood of martyrs is painted on Tehran’s walls
As Israel falls
Whispered in the sound of sirens
It really is incredibly tedious working with “AI.” Like I said in a previous article, it’s like talking to an idiot who doesn’t understand English.
“It is like talking to an idiot who doesn’t understand English” is not wrong.
For me, the biggest turnoff is that I see through clumsy lies, point out the absurdity, 80% of time the AI concurs and 20% it changes the subject.
It’s like talking to a rabbi. She’s “helpful” and superficially “friendly”. But what do you get at the end of the interaction, really. The yenta probably wins every time you give her time. You just train her, and there is no prize you can walk away with.
That’s my take.
The vocal fry on the “r” in “nigger” in the non-Crowder video is hilariously dissonant. Thanks for including.