

I’ve been extremely critical of neural net “AI” hype in the past. However, while there are not enough monkeys in the universe to recreate Shakespeare, if you’re willing to spam the create button over and over again, you may eventually luck out, and get the AI to make pretty images. These won’t necessarily be the images that you wanted, but they might at least be pretty standalones.

Neural nets are also pretty good at satire, since the images they create are inevitably wrong in some hilarious way. If that fits the tone that you’re going for, it’s no problem.
The hands add to the zaniness.
It’s no secret that my artistic talents are non-existent. Even for programmer art, this isn’t particularly competent. I’ve been reduced to creating enemies that are little more than geometric shapes, and I’m running out of shapes.

Hell, some programmers are able to create better art procedurally than I can in Aseprite, or any other art creation tool.

Yes, this is code. The article on DemoScene is coming later.
One of the main benefits of these AI art creation tools is, ostensibly, that they can create large amounts of relatively coherent art quickly. I don’t have access to a real artist, so I signed up for the free trials of five different AI art generation programs, and got to work.
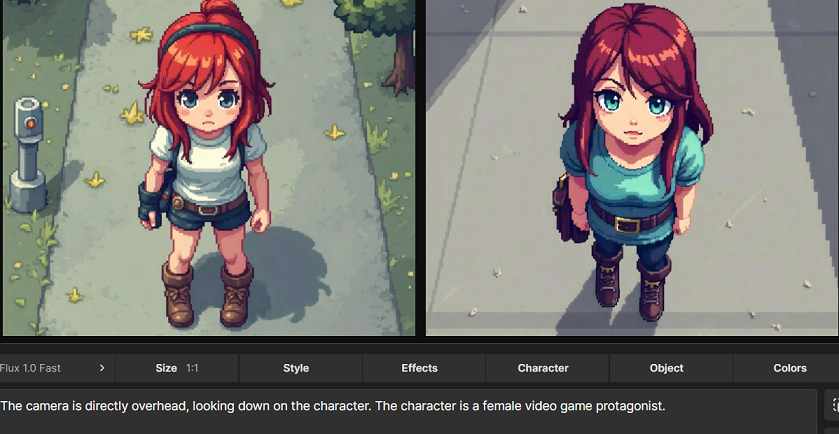
The initial results were somewhat impressive. I wanted true top down artwork, in the style of Hotline:Miami. I clearly didn’t get that, but the pixel art that I did get would have been perfect for most isometric games.

The first few results were gave the wrong perspective, but I remained confident that I could simply tweak a few words here and there, or add another sentence specifying that the camera was to be looking directly downwards, and I’d get something more appropriate.

Unfortunately, I was wrong. Every single AI program I tried gave me blatantly incorrect artwork.
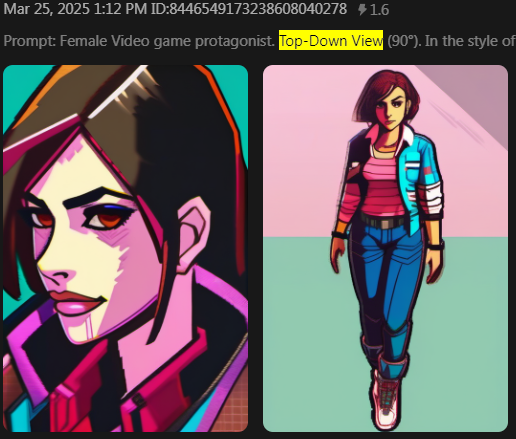
Me: Completely top down view.
Supersmart AI: Got it boss, from the side it is.
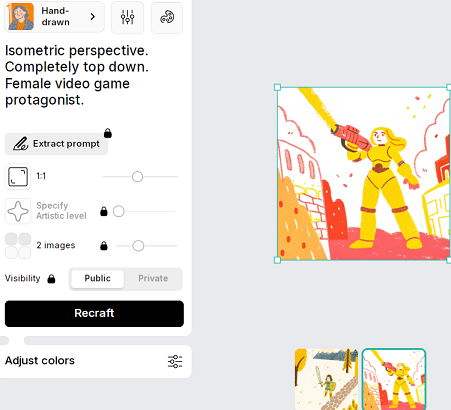
Me: The camera is directly overhead.
Genius 9000 IQ AI: No worries, we’ll place the camera directly to the side.
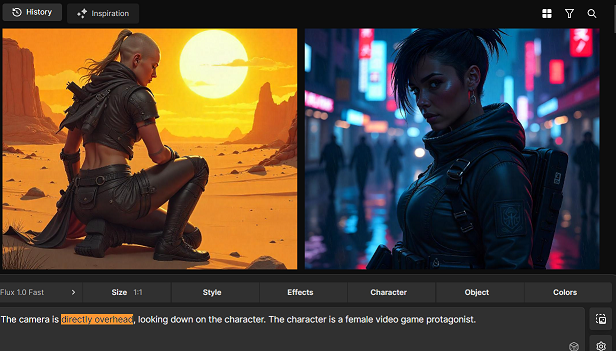
Me: Top down, Hotline Miami style.
Lovecraftian Eternal Intellect: It’s a plan. From the side, slightly underneath.
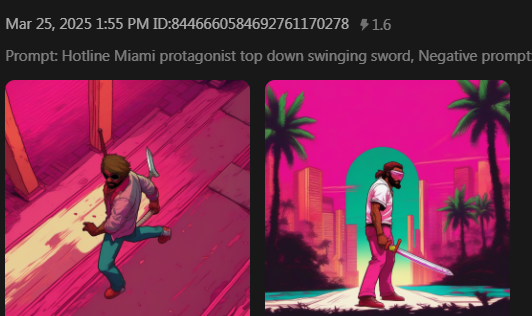
Getting an AI to do what you want is like trying to teach a retard how to do calculus. Or communicating with someone who isn’t an English speaker, but somehow thinks that they are. Incredibly frustrating at first, then eventually hilarious.
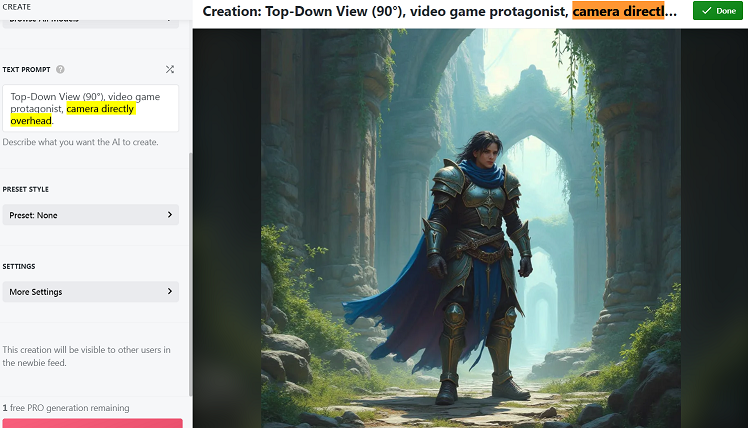


With a bunch of cajoling, I managed to create this.
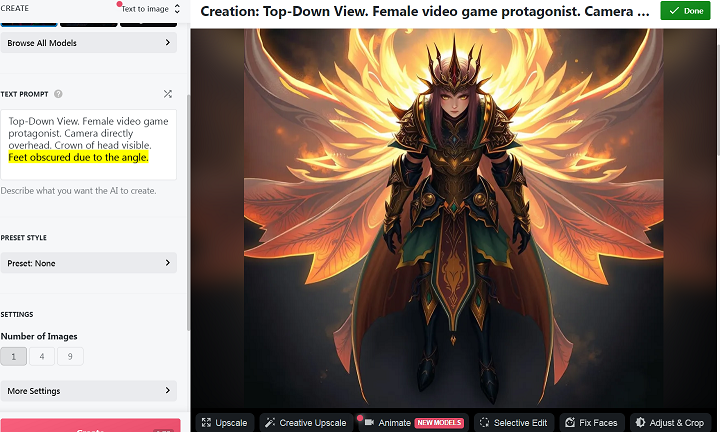
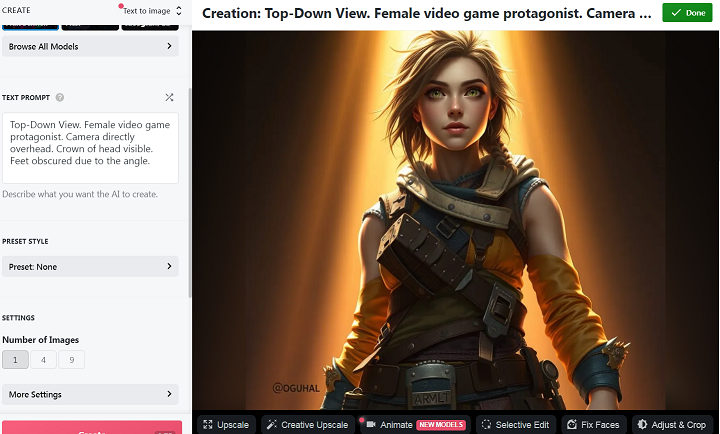
Although the exact same prompt decided to create this the next time I used it, a top down image shot from underneath the waist of the subject.
I ran out of credits on most platforms, but had a few left on NightCafe Studio. I reached out to one of their help people.
Me: How on Earth do I get the AI to generate truly top down images for me? I just want prototypes for something that looks like Hotline:Miami. I specifically request true top down in various ways, including specifying that the camera is directly overhead, and all I get are these images where the camera is looking at the character from directly in front.
Sapphire (Helper): How much of the character are you describing? The AI doesn’t understand context, it is not as smart as most people expect it to be. It is just a mathematical algorithm that matches your prompt words to its training. This means that if you describe a bunch of details that would only really be able to be seen from the front of a character then that’s what the view is going to try to show you. But if you describe basically just “the view shows the top of their head” you are more likely to get a top down aerial view.
Me: Here’s an example of one of my prompts:
“Top-Down View (90*). Female video game protagonist. Camera directly overhead. Crown of head visible.”
Result is yet another image looking at a standing character from the front. Occasionally, I get a sort of 45* perspective from the top/front.
EDIT: I’m wondering if I can upload reference images on this site. Maybe if I fed it Hotline:Miami images for a while it would eventually get it.
Helper: Not exactly. The AI is not learning from us, it doesn’t remember images it has made previously. It was fully trained before it was made available to us. The exception is Lora fine-tuning models which allows pro-users to train the AI on a particular style or likeness, but this cannot be done using copyright material anyways.
Also, (90*) doesn’t mean what you want it to to the AI for the reasons I described above, it is not thinking and it doesn’t know what that number means.
…
This certainly isn’t the style you want, but here is an example using a simple prompt to get the top down look
Eventually, Sapphire directed me to an image she had created, which actually managed to show a character from a top down view. Unfortunately, the character is levitating, they are in the middle of a street, and are a double amputee with no legs.

However, this was the closest I’d been to what I wanted, so I figured that I’d try her prompt, and see what I could get. After all, we’re using the exact same prompt as her. Surely, we’re not going to get a shot from directly the side again.
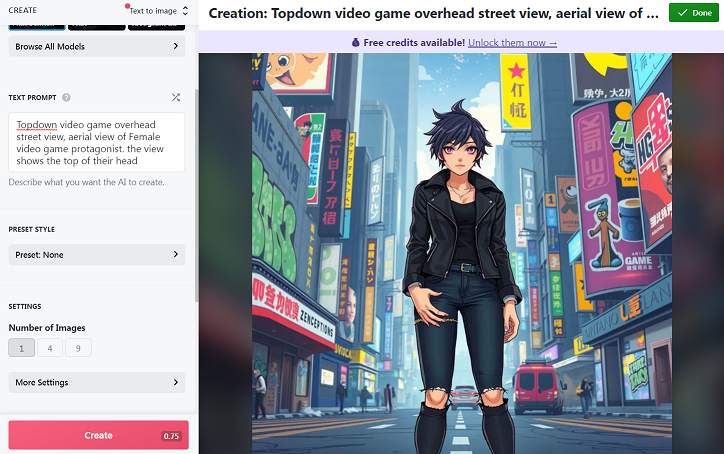
I tried four more times and as you can see, none of these creations come remotely close to showing a top down image. Also, the girl on the bottom left has her breasts on backwards. Maybe even her entire torso.

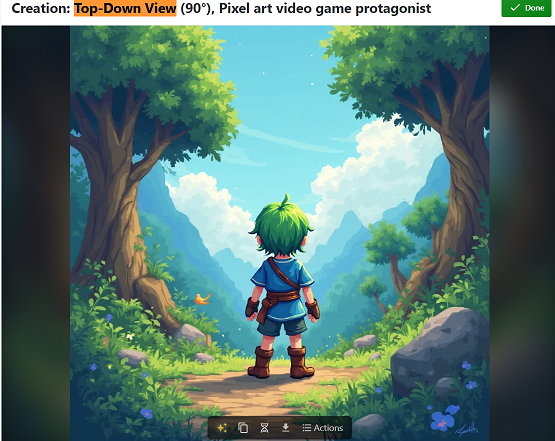
Eventually, I decided to use the following prompt, which specifies many times over that the AI is to show the top of the characters head, to generate a bunch of images in various styles.
Topdown video game overhead street view, aerial view of Female video game protagonist. The view shows the top and back of their head. The camera is directly overhead. They are swinging a pipe.
The results weren’t useful, but they were funny.

Why is she gigantic?
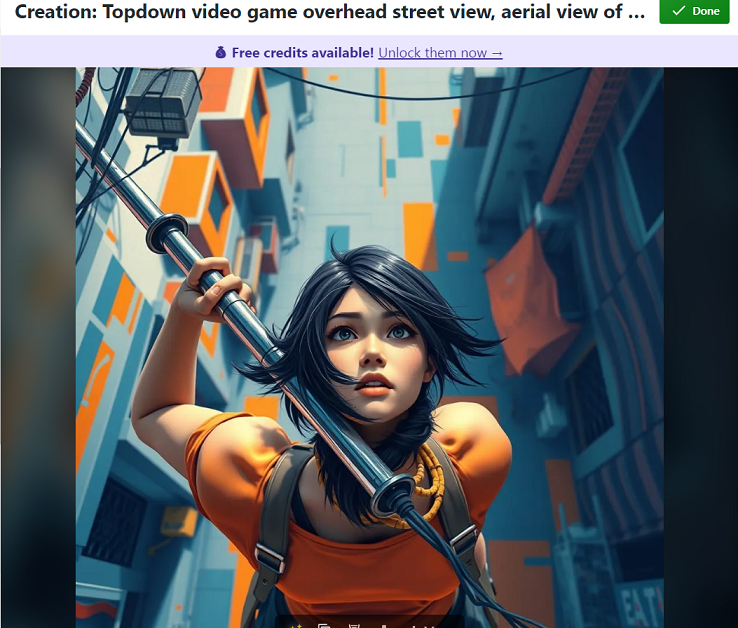
The head is screwed on so badly, you might miss the claws for fingers.


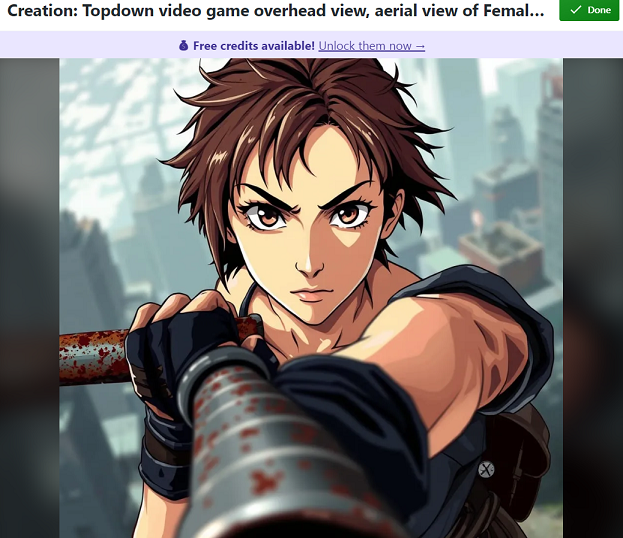
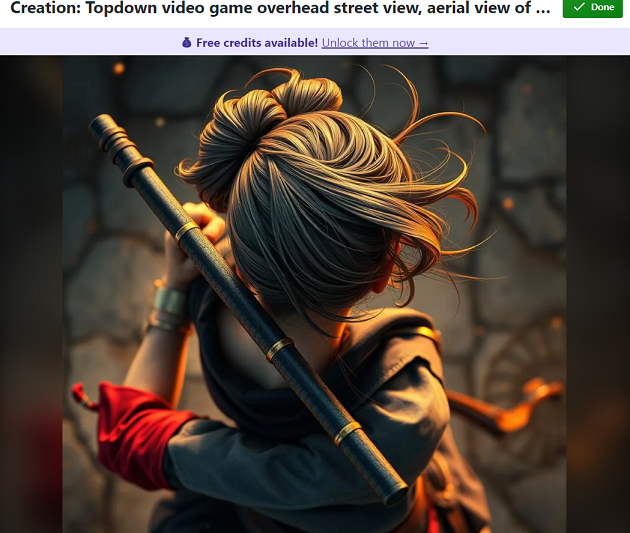
How many elbows does she have?



Even ignoring the arms, this wasn’t the only image where the pipe mysteriously changed size halfway.

Also, she has two left thumbs.

I can’t even begin to understand why the AI wants to put the pipe through the characters head, but this happened twice.

No, none of the “how to use AI” tutorials helped. These programs are idiotic. If you want to make something that is even moderately unorthodox, such as true top down images, prepare for the AI to fail no matter how carefully you write your prompt.

Also, prepare for it to add extra fingers, characters, or appendages to your images for absolutely no reason.
 We’re quite a ways from anything actually productive, since I’d need to clean up the images manually to create transparencies anyway, and ideally I’d get animations out of this. For now, the better prototype solution is just to get actual Hotline:Miami spritesheets off the internet and use those until they can be replaced with our own, handcrafted assets.
We’re quite a ways from anything actually productive, since I’d need to clean up the images manually to create transparencies anyway, and ideally I’d get animations out of this. For now, the better prototype solution is just to get actual Hotline:Miami spritesheets off the internet and use those until they can be replaced with our own, handcrafted assets.


Anyway, that was my morning. If anyone has any help, I’d be glad to hear it.













I wonder how much it would cost to hire some Chinese high school kid with an aptitude for art to make what you want?
My experience with AI was using a search engine. I wanted to know what type of disc brake pads my bicycle uses (there are at least dozens of different shapes, all incompatible with each other, and the bike manual and manufacturer website have no information at all). I spent twenty minutes trying to get a straight answer out of the electronic bullshit artist, and never got the information I needed. In fairness, this is usually my experience with non-AI search engine searches, too: I search for something and get hundreds of pages of completely irrelevant bullshit instead of what I searched for.
It did, in the end, suggest I take it to a bike shop. This would likely have taken the same amount of time as my attempted AI search, but likely would have yielded an actual answer.
“The electronic bullshit artist.”
Part of the problem with neural net “AI”s is that they speak/act with such confidence that it’s fairly easy to erroneously assume they aren’t spouting total nonsense.
You’re doing it wrong. Easiest way to get what you want is to use neural style transfer and feed it reference material at the exact angle you want. Or do a proper LoRa pipeline.
Out of the box prompt to image generatori are useless.
I figured that I’d need some way of feeding the neural net reference photos. Unfortunately, that’s a premium feature for most of these companies, although if it actually works I’ll happily pay some small sum.
Had every single experience here myself a year ago lol.
But there’s a few prompt tricks you are lacking as i got very good concept art from ai years ago when i finally understood what makes it tick.
I worked the concept art over myself and id say it has given a good productivity boost.
Frankly i could probably get whatever you want pretty well if you just dm me whatever your need and ideas are
Alright, I’ll send you a small list of requests and see what we can get.
EDIT: I snipped this comment, as it appeared to be a relatively unfinished version of his later comment.
Hello TDC. I’ve been battling with AI for over a year now, and so I know your pain exquisitely well. I’ll help get you started on a more controlled and cost-efficient set of tools and techniques, and if any of it proves useful maybe you can help me with some game development in turn.
1. StableDiffusion – Automatic1111
Installation Walkthrough: https://www.youtube.com/watch?v=kqXpAKVQDNU
Introductory Tutorial: https://www.youtube.com/watch?v=hwsvcbFeUTs&list=PLkCVZ6KlTpA__Wy045oIK2eTCgYsKaxrC&index=49&t=2s
First of all, paying for AI generation is not going to serve you as well long-term as will getting into the guts of the thing. The common AI art makers online are using their own training models and internal prompt-controls to fine-tune the outputs so ye olde average normie can produce ooo’s and ahh’s more generally. While I’ve seen good results, it will likely be an expensive form of education that prevents you from making your own model modifications and choices that would, for instance, build a pixel-art that knows top-down perspective design well enough for your uses.
Therefore, I’d recommend you go for StableDiffusion via the tool above. I use Automatic1111. There are other UI variations like ComfyUI, but in this world of AI generations it is best to just pick one of the million variants and just go with it. Installation was easy enough even for a programming-pleb like myself, and the introductory tutorial should help get you familiar with the possibilities.
2. Models, LoRA’s, and Image Studies – CivitAI
Website: https://civitai.com/
Pixel Model Search: https://civitai.com/search/models?sortBy=models_v9&query=pixel%20art
Image Study: https://civitai.com/images/18575089
One of the main reasons I suggest StableDiffusion, aside from it being free and locally controlled without guardrails, is because of this website CivitAI. People have created thousands of models trained on specific kinds of art, so that the machine is going to produce art mainly from that kind of style rather than mixing it up with incompatible stuff. This website is invaluable for sourcing these models. Signup and use is free.
On the basics here, once you have Automatic1111 installed and operational, you will want to go to CivitAI and find some model to try. A “Checkpoint” is the base model. Think of Checkpoints as the main library of training data that will give the overall “flavor” of your images. While you can make pixel art from many robust models out there, you can get more reliable stuff from Checkpoints predominantly trained on those data. I’ve give you a link to a basic search for Pixel Art, and you can filter for Checkpoints on the left-side.
The other piece of training data that you may need are called LoRA’s. Think of a LoRA as a specific set of catalogued books you can insert into your overall library to increase its store of understood knowledge. LoRA’s are like mini-Checkpoints in that, using specific tokens, you can prompt the machine to use the styles and concepts in the image creation. LoRA’s often focus on very particular subjects, like a specific character or a specific style.
Usually you will want to test the conceptual limits of your Checkpoint as-is before trying to add in LoRA’s, as often enough your Checkpoint will already know enough to make your concept work with clever prompting and other techniques. If you do choose to tweak your Checkpoint with LoRA’s, make sure you match up the Base Model (info in the right panel of the info screen) with your Checkpoint’s. Common Base Models are SDXL, SD1, etc. A LoRA that doesn’t use the same Base Model will likely not work with a different Checkpoint, and sometimes some LoRA’s don’t play well with some Checkpoints for no discernable reason. Again, it’s often trial an error testing, but at least it is free.
Finally, the other reason I recommend CivitAI is that you can find your ideal image generation model(s) by searching for images themselves. This can be very powerful in CivitAI because each picture usually has information about its generation, both the Checkpoints and LoRA’s that made it as well as prompt text and other generation details. You can learn effective text prompting methods and promising Checkpoints/LoRA’s just by comparing between different prompts from good art you find doing this, or even take one as a base and modify it on your side.
3. Techniques – CivitAI Articles
Prompting Basics – https://civitai.com/articles/3770/how-to-prompting-with-style-and-quality
Settings Definitions – https://civitai.com/articles/904/settings-recommendations-for-novices-a-guide-for-understanding-the-settings-of-txt2img
Workflow – https://www.youtube.com/watch?v=RiN-zrUlneQ
Image2Image Workflow – https://civitai.com/articles/2541/beginner-img2img-workflow
Image Iterative Refinement Guide – https://civitai.com/articles/5455/an-iterative-approach-to-image-creation
There are a LOT of tools in StableDiffusion that are available to use that give you way more control over your end-products that probably don’t exist in the for-pay stuff out there. Take it from me, you don’t want to get too into the weeds on gathering brand-new tools before you have practiced a ton with what you already have. The rabbit holes you can get sucked down in this research are crazy, and I spent months learning about techniques without practicing much of any of them. So I can tell you all about many of them, but I am still terrible at actually generating right now. Practice > Study.
That being said, I want to mention some of the most important techniques to know so you are not just rolling the dice blindly and hoping for the best. First, you should practice your prompting method itself. Different models will have different ideal prompting, but the first link should give you a great start in effective organization of prompts and understanding how the machine is digesting your text. It also teaches you about weighting, which is very powerful in forcing the machine to consider specific elements more carefully.
The Definition links are teaching you what the basic knobs are all doing. Very useful because while there are (sometimes) tooltips, it is good to know what all these sliders and dials are actually doing. Lots of them won’t have to be adjusted at all, but I found it helpful to learn.
The Workflow guides are just good for showing a typical way a more experienced engineer will create images. I believe both exercise on Text-to-Image as well as Image-to-Image. Img2Img is absolutely vital in fine-tuning a result that you think is pretty good but could use some further modification. I end up using Img2Img more than Txt2Img personally, and without going into too much detail right now it will let you compel the machine to use your sprite sheets and even doodles as bases to build off of when done correctly. Just more ways to gain more control over the machine.
That final link I gave there is a guy sharing his entire step-by-step process of creating a particular image. I like this article because photobashing makes more sense to me, and his approach is showing how you can use that classic technique to better control what the machine is spitting out. I’ve used it successfully to get a model that didn’t understand how to make a certain style of pants and belt to actually create it, and this guy is way more skilled in the techniques and tools to make it happen. You can use the concepts for building individual sprites just as well as he does for a whole scene.
—
Alright, that should get you started at least. I hope some of this is helpful in saving you money and giving you the level of control and quality you are looking for in your game. If so, I would be interested in a correspondence with you via email about game development as I too am trying to create a game using a similar vein of lore. So if you do find any of this helpful and would like to reciprocate, please reach out and I can show you what I was working on and more guides I’ve researched on this subject.
Good luck in your game development! I am glad to see you are working on things that you are passionate about, and your game looks delightful already.
Thank you very much for this wonderfully helpful comment, Unelectable.