

Hope you don’t mind your autopiloted Tesla steering wildly into the next lane because some paint got dripped on the road.
An integral part of the autopilot system in Tesla’s cars is a deep neural network that identifies lane markings in camera images. Neural networks “see” things much differently than we do, and it’s not always obvious why, even to the people that create and train them. Usually, researchers train neural networks by showing them an enormous number of pictures of something (like a street) with things like lane markings explicitly labeled, often by humans. The network will gradually learn to identify lane markings based on similarities that it detects across the labeled dataset, but exactly what those similarities are can be very abstract.
I actually have something to add here. Neural Net AI has this enormous limitation that’s rarely talked about, which is that even the people who work on them can’t actually tell you why the neural net is getting the right results. They just eventually change their weights more and slowly narrow in on the correct answer.
This is a serious problem for something like a Chess AI. In 2019 Google’s Deep Mind sub-corporation, it’s complicated, released some games where they had their neural net AI program winning versus Stockfish 8. Well this wasn’t the most up to date version of Stockfish, but it was still impressive. The playing style was very “human-like,” compared to traditional chess engines.
LONG TECHNICAL DISCUSSION INCOMING.
The way that traditional chess engines figure out how to play well is by having some method of evaluation a position, and some other method of calculating possible moves and countermoves in advance. Contrary to the common misconception that chess engines “see everything up to the depth they calculate,” this is simply not true. The average legal moves in a position is around 35. Sometimes more, sometimes less. That means that if I take a turn, I can make 35 moves. On your turn you can take 35 moves for each of my 35 moves. This works out to about 1,000 unique positions after we each make one move.
And the problem is after two moves we aren’t up to 2,000 positions, but rather 1,000*1,000 positions, or one million. After three moves we’re already at 1 billion positions to evaluate. After four moves we’re at one trillion. Even if evaluating a single move took only a single CPU cycle, which is ridiculous, a CPU running at 5 GHz, or 5 billion cycles/s, would need 200 seconds to evaluate all those positions. At just 5 moves deep per side, we are evaluating one quadrillion positions. That would take 200,000 seconds, or 55 hours to evaluate. This is clearly a non-starter.

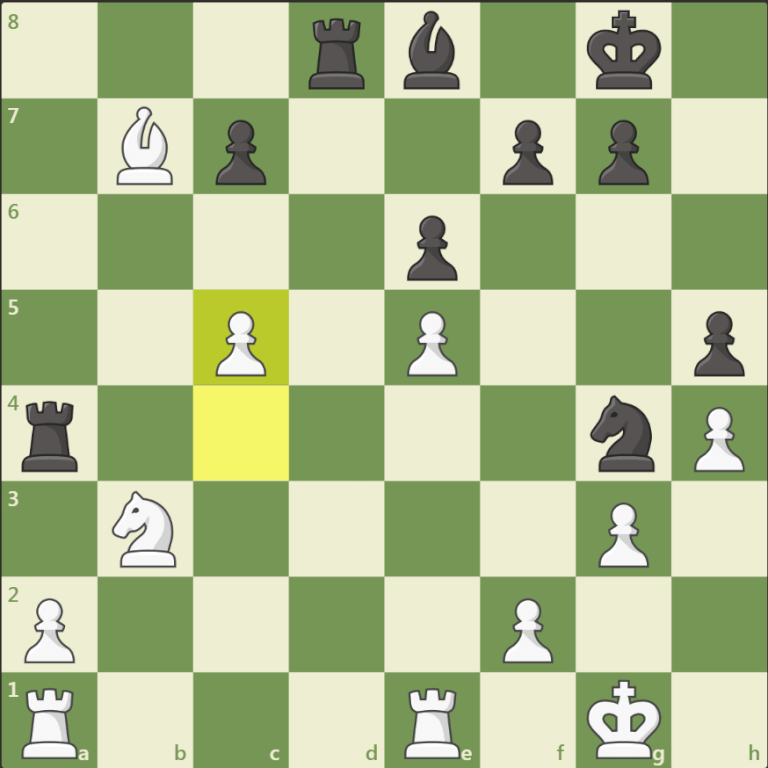
The good news is that most moves are idiotic. In the above position, after Rf4, White has a few decent options to pick from. He can take Rxd4, or cxd4. He can also think about g3, attacking the rook, which was played in the game, and is a huge blunder after the exchange sacrifice dxe3. D6 could also be good, and maybe Nf5. No other moves need to even be considered. If we play a stupid move like Kf1, then black simply takes our rook. We can play other silly moves like Qg6 or Qh7+, which simply give away the queen.
I went and counted up all the legal moves that White has. It comes to 8 pawn moves, 5 knight moves, 3 king moves, 10 queen moves, and 7 total rook moves. That gives us 33 legal moves, of which only 5 are not idiotic. If we only had to calculate 5 moves per turn, then after 5 per side instead of one quadrillion positions to evaluate, we have only 9,765,625. That’s not a typo, we have literally 100 million times fewer positions to evaluate. That’s just 0.000001% the positions, showing the power of compound interest.
Getting rid of stupid moves early allows us to calculate a select few lines much deeper. A lot of the work done by chess engine programmers is doing this step well, where they prune down the options aggressively, without missing too much. After all, occasionally extremely weird moves tactically work.

And yet Alpha Zero had a traditional, stupid, depth first search. That means it just looks at all possible moves, but to a much shallower depth. Yet, it still beat the traditional engines, and a similar style program, Leela Chess Zero, also built with neural network evaluation, beat Stockfish and was the top chess engine for a while.
The problem with the traditional chess engines was that their positional evaluation was poor. They were very materialistic, meaning that they counted up the material on the board and that was that. The positional evaluation of these engines was somewhat kindergarten level. They’d not make obvious positional blunders, like closing off their bishops, or getting the knight trapped on the edge of the board for no reason, but for the most part they could be thought of as 1500 players who were given superhuman calculation abilities.
A blunder by Ian Nepomniachtchi in the world championship versus Magnus Carlsen. Can you punish this move?
In contrast, the neural net programs appeared to have a much more sophisticated evaluation of the position. Almost more interesting than the games AlphaZero won, were the games that it lost. A good example is below.
Traditional chess engines never did “speculative sacrifices.” As I mentioned earlier, if they sacrificed material, they needed to have very concrete tactical justification, or at least an overwhelmingly obvious positional advantage at the end. In contrast, AlphaZero just thinks “well my pieces are active, so that’s good.” As a result, it appears to play a much more “human” like style. Basically it thinks that the long term advantages it has, like better piece activity, will eventually lead to it winning. Stockfish allowed it to sacrifice material, since it couldn’t figure out the concrete advantage that AlphaZero would get. Like I said, it’s speculative.
AlphaZero appeared to have this very human-like playing style, and yet Google claims that all they told it was how to play chess. How could this be possible? Shouldn’t we have to handcode some positional knowledge, like that passed pawns are good, piece activity, king safety, etcetera?
Well just knowing the material count, position of the pieces, and possible moves lets a few heuristics be developed. Obviously material count is the most obvious. Despite never being told that a Queen is worth 9.5 points of material, a bishop 3, and so on, playing millions of games hammers home that a queen is far more valuable than a bishop. Eventually very accurate piece evaluations can be achieved.
But even more abstract concepts can be figured out as well. There is a concept in chess called controlling the center. The way the Neural Net might find that out is noticing that when its pieces can move to the center squares it wins more often, and the opposite for the other side. Piece activity can be crudely figured out through the principle that the more moves a piece has, especially towards important squares, the better. King safety can also be crudely approximated by counting up the number of potential checks in a position. Additionally, moves where you control the square the enemy king is on or around, is good. Doubled pawns could be organically found to be bad, since the neural net could evaluate positions where there are no pawn moves to defend each other as being bad. Same for passed pawns.

Above is a good example. Material is even, but the White Knight is miles better than the Black Bishop.
But that’s the thing, we never really know how a neural net figures out anything. In a traditional chess engine we’d handcode all these positional evaluation tricks. For the neural net, all it knows is what moves are legal, what material is on the board, and where, and then does massively complicated evaluation based on that. It’s also why neural net engines are utterly useless for a fun game versus the computer. They have no way of not simply crushing you.
Chess engines are miles better than people, but traditional engines can be hand coded to make mistakes, simulating a lower level of play. They often don’t do this particularly well, and make “computer-bad,” moves as opposed to realistic bad moves, but at least it’s possible. With more work they could be convincing. Neural nets can’t possibly do this. They receive the input, which is the position on the board, and spit out the output, which is their move.

If you’re wondering where I’m going with all this, well you’ll see in a second.
Because of this disconnect between what lane markings actually are and what a neural network thinks they are, even highly accurate neural networks can be tricked through “adversarial” images, which are carefully constructed to exploit this kind of pattern recognition. Last week, researchers from Tencent’s Keen Security Lab showed [PDF] how to trick the lane detection system in a Tesla Model S to both hide lane markings that would be visible to a human, and create markings that a human would ignore, which (under some specific circumstances) can cause the Tesla’s autopilot to swerve into the wrong lane without warning.
Usually, adversarial image attacks are carried out digitally, by feeding a neural network altered images directly. It’s much more difficult to carry out a real-world attack on a neural network, because it’s harder to control what the network sees. But physical adversarial attacks may also be a serious concern, because they don’t require direct access to the system being exploited—the system just has to be able to see the adversarial pattern, and it’s compromised.
The initial step in Tencent’s testing involved direct access to Tesla’s software. Researchers showed the lane detection system a variety of digital images of lane markings to establish its detection parameters. As output, the system specified the coordinates of any lanes that it detected in the input image. By using “a variety of optimization algorithms to mutate the lane and the area around it,” Tencent found several different types of “adversarial example[s] that [are similar to] the original image but can disable the lane recognition function.” Essentially, Tencent managed to find the point at which the confidence threshold of Tesla’s lane-detecting neural network goes from “not a lane” to “lane” or vice-versa, and used that as a reference point to generate the adversarial lane markings. Here are a few of them:

Above we see Tesla’s lane detection neural net doing a very good job. It correctly sifts through the noise and faintness and identifies the left lane as a lane. It takes an extremely messed up or broken lane for the neural net to not identify it as a lane. Probably on par with a human observer.
Except that’s the problem. It’s too good at identifying things as lanes that it does so with things that are obviously not lanes.

Here we see three dots on the ground. No real person would identify this as a lane, and yet Tesla’s neural net is quite certain that this is a lane, which is ridiculous. And it’s not a trivial task for Tesla to de-train seeing this as a lane, because then they might incorrectly interpret many dotted lanes as not lanes, and swerve into traffic.
In situations like that, we do what humans are very good at—we assimilate a bunch of information very quickly, using contextual cues and our lifelong knowledge of roads to make the best decision possible. Autonomous systems are notoriously bad at doing this, but there are still plenty of ways in which Tesla’s autopilot could leverage other data to make better decisions than it could by looking at lane markings alone. The easiest one is probably what the vehicles in front of you are doing, since following them is likely the safest course of action, even if they’re not choosing the same path that you would.
My family got a black cat once. She had white paws and a white underbelly. I lost track of how many times, especially when she was a kitten, that I thought I saw her out of the corner of my eye, before realizing that I was simply staring at some random thing that was most definitely not a cat.
The chemical receptors in your eye have a low firing rate, something like 10 Hz. To make up for this, they don’t all fire at the same time. What that means is that only a small part of your eye is actually seeing at any one time. Your brain has to process the results, and interpret them through context. Since we had a black and white kitty who would regularly be curled up into odd shapes, without conscious thought my brain interpreted almost everything as her.
You can never get this sort of context with an automated system. People will always be better at identifying what a lane is, because we can provide the obvious context of “I expect there will be a lane here,” which an automated system simply can’t reliably do. Beyond that, you can move your neck around to get more visual information as to what’s going on, along with your ears providing more context that you might not be consciously aware of.

The problem Tesla’s lane recognition neural net has is classic. The above neural net was trained to never mistakenly miss a dog in a picture, so it thinks everything with legs is a dog, no matter how ridiculous. It trades having fewer false negatives with way more false positives.

On the left we have the original image. On the right we have a neural net trying to “enhance,” the image. Sort of like how a neural net, or your brain, will “enhance,” a broken lane and understand that it’s all one lane, the neural net here “enhances,” the sky and understands that it’s full of dogs. It also “enhances,” the bottom of the grass into a village.
Hallucinates might be the more appropriate term, and that’s what people should understand about neural nets. They aren’t actual AI, they’re just stupid programs that are trained to respond to patterns. And sometimes they fail spectacularly.
That’s what people mean when they say that neural nets are very susceptible to “adversarial images,” or “adversarial attacks.” The layman’s term is “they’re easy to fuck with.” As long as the images that they are being fed are different from the images that they were taught on, there’s a good chance for catastrophic failure, that simply never happens with people.
I’ll write up about Google’s fraudulent claims of AlphaStar “destroying,” the best Starcraft 2 players in the world at some other time. For now just understand that while there may be some small benefit here or there, for the most part when people are talking about “muh AI revolution,” they’re entirely full of shit. It might be true that the crashes caused by Tesla’s autopilot system are fewer than the crashes caused by human error. It’s plausible that for highway driving this would be true. It’s just that Tesla has never actually proven that this is the case, and there’s a great deal of reason to not want to put your life in Elon Musk’s hands.













This is a pretty good video about tricking neural networks
https://youtu.be/cpxtd-FKY1Y
I love dogs, and I thinks its hilarious that the neural network just puts dogs everywhere. Its like doing DMT and having a dog themed trip, where the texture of everything turns into dogs.