

Yesterday I wrote about Tesla’s autopilot AI, and it’s serious flaws. A few years ago neural network AI was absolutely all the rage. There were articles implying that we were about ready to see our new AI overlords taking over.
Above we see something admittedly quite impressive. Given nothing more than the goal of getting from one side to the other, and complete understanding of the terrain, the neural nets managed to walk from one side of the arena to the other. Yes, they used some crazy walking animations to get there, but they did it. It’s also highly likely that handcrafted animations could have done all that and better, but it’s still cool that they managed to walk at all. Even if it looked super derpy.

The weird walking animations, while cute, actually show a serious problem with neural networks. Oftentimes they learn one way, but can’t learn the most efficient way. Changing the arm movement for the run animation to something normal wouldn’t work for the leg animation. Changing the stride to something normal wouldn’t work with the arms. The neural net has to luck into both of those changing at the same time, in the same direction.
Except that it’s not even as simple as arms and legs. Every joint would need to synchronously mutate in the right way to get a more productive run animation. That’s the ankle joint, the knee, the hips, the shoulder, and the elbow, and one for each side. All of them would need to mutate in the best way so as to have the creature remain balanced.

That’s why the four legged spider creature and the no arms creature had the most reasonable looking walks. Since there were less moving parts, it was exponentially easier for it to mutate in the correct way, where correct here means most efficient and logical walk/run pattern.
It’s not hard to understand why something like this happens. I’ll bet that the above creatures are extremely well balanced, or they gave it a rough animation to start with. If not, you’d risk a situation where it simply falls forward, and thinks this is better than other things, since it’s closer to the end. Then it optimizes falling forwards, maybe with a jump, instead of walking. It’s easier for it to optimize falling forwards better, and there’s no way for it to mutate from falling forwards to the totally different movement of walking. This is called a local optimum.
This is also why most neural net AIs, including the starcraft ones, and the chess ones, get a trainer set. While Google bullshits about how “Alphazero was only taught the rules of chess,” that’s just flat out not true. They quietly admit that they downloaded tens of thousands of amateur chess games with Stockfish evaluation, and gave those to alphazero so that it could start with a very reasonable chess ability and not do dumb things like “fall forwards instead of walking.”
Neural Net AIs not learning properly is going to be a running theme of this article. But first we start with the irrational hype.
After laying waste to the best Go players in the world, DeepMind has moved on to computer games. The Google-owned artificial intelligence company has been fine-tuning its AI to take on StarCraft II and today showed off its first head-to-head matches against professional gamers. The AI agent, named AlphaStar, managed to pick up 10 wins against StarCraft II pros TLO and MaNa in two separate five-game series that originally took place back in December. After racking up 10 straight losses, the pros finally scored a win against the AI when MaNa took on AlphaStar in a live match streamed by Blizzard and DeepMind.
The pros and AlphaStar played their games on the map Catalyst using a slightly outdated version of StarCraft II that was designed to enable AI research. While TLO said during a stream that he felt confident he would be able to top the AI agent, AlphaStar managed to win all five games, unleashing completely unique strategies each time.

This sort of breathtaking analysis is fairly typical of pop-science garbage. Alphastar didn’t “use different strategies each time.” Instead there were multiple version of alphastar that had each learned one play style and only one play style. As a result, had they played against the pros multiple times the pros would have begun massively exploiting their weaknesses. Since this wasn’t the bullshit hype that Google wanted, they didn’t allow that.
AlphaStar had a bit of an advantage going up against TLO. First, the match used the Protoss class of units, which is not TLO’s preferred race in the game. Additionally, AlphaStar sees the game in a different way than your average player. While it is still restricted in view by the fog of war, it essentially sees the map entirely zoomed out. That means it can process a bit of information about visible enemy units as well as its own base and doesn’t have to split its time to focus on different parts of the map the same way a human player would have to.

What alphastar sees.
To clarify, alphastar can’t see anything in the fog of war. That’s an area not illuminated by any of their units or buildings. However, unlike the human players, who have to waste time moving around with the camera, alphastar can see the entire map no problem. But the retarded endgadget journalist claims that this large advantage is more than made up for by APM limitations put on alphastar.
Still, AlphaStar didn’t benefit from the type of benefits that one might imagine an AI to have over a human. While TLO and MaNa are theoretically limited in how many clicks they can physically perform per minute in a way that an AI isn’t, AlphaStar actually performed fewer actions per minute than his human opponent and significantly fewer than the average pro player would use. The AI also had a reaction time of about 350 milliseconds, which is slower than most pros. While the AI took its time, it was able to make smarter and more efficient decisions that gave it an edge.

Since I know what’s coming I know how utterly laughable that statement is. Still, he includes this helpful graph of APM provided by Google’s DeepMind team.
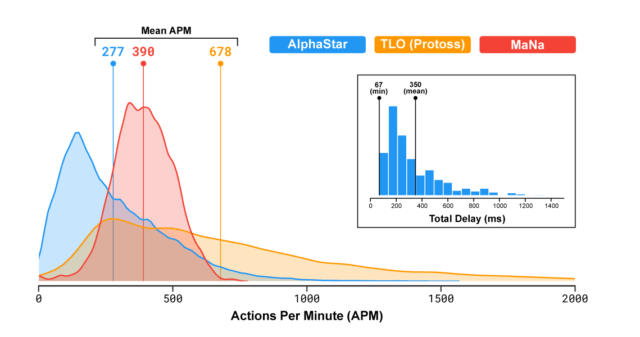
This is a measurement of how many Actions Per Minute were being performed by each player, each second. If that sounds confusing it’s like measuring how fast your car is going in miles per hour, each second. However, contrary to what the propagandist claims, APM in Starcraft are not clicks. We’ll get to why this is extremely important later.
The pro player MaNa peaks around 600, with a normal distribution. Alphastar has this absurdly long tail, where it had over 1500 actions per second for at least one second. However, Google assures us that this is okay, because the human player TLO had bursts of over 2000 APM/s, and even averaged considerably higher for the entire match.
Last week DeepMind invited two professional StarCraft players and announcers to provide commentary as they replayed some of AlphaStar’s 10 games against Wünsch and Komincz. The commentators were blown away by AlphaStar’s “micro” capabilities—the ability to make quick tactical decisions in the heat of battle.
This ability was most obvious in Game 4 of AlphaStar’s series against Komincz. Komincz was the stronger of the two human players AlphaStar faced, and Game 4 was the closest Komincz came to winning during the five-game series. The climactic battle of the game pitted a Komincz army composed of several different unit types (mostly Immortals, Archons, and Zealots) against an AlphaStar army composed entirely of Stalkers.
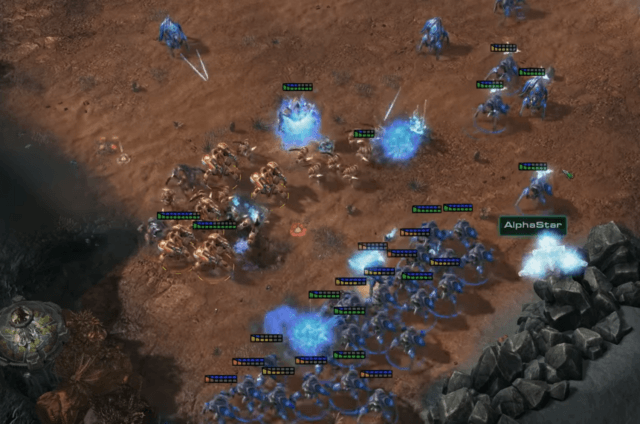
The battle.
Stalkers don’t have particularly strong weapons and armor, so they’ll generally lose against Immortals and Archons in a head-to-head fight. But Stalkers move fast, and they have a capability called “blink” that allows them to teleport a short distance.
That created an opportunity for AlphaStar: it could attack with a big group of Stalkers, have the front row of stalkers take some damage, and then blink them to the rear of the army before they got killed. Stalker shields gradually recharge, so by continuously rotating their troops, AlphaStar was able to do a lot of damage to the enemy while losing very few of its own units.
In other words, the computer used its insane APM advantage to break the game, and have an inferior army destroy a much better one. I’ll explain how we square this with Google’s bullshit about “no APM advantage,” later.
Commentators watching the climactic Game 4 battle between AlphaStar and Komincz marveled at AlphaStar’s micro abilities.
“It’s incredibly difficult to do this in a game of StarCraft II, where you micro units on the south side of your screen, but at the same time you also have to do it on the north side,” said commentator Kevin “RotterdaM” van der Kooi. “This is phenomenally good control.”

I gave credit where credit was due in my last piece to Alphazero, the chess engine. While the computer can calculate many more moves deep than a human, Alphazero had noticeably different strategy compared to traditional chess engines. It was far more human-like, being less materialistic. It also had some quirks, like pushing the flank pawns, that, while not unseen at the highest level of chess, nevertheless lead to some 2700+ players changing their style somewhat.
There was some hope that alphastar could do the same for Starcraft. And yet 100% of starcraft pro players and commentators were convinced that there were zero strategic insights found by any of the versions of alphastar. The consensus was that it simply massively outclicked the human opposition, breaking the game and getting away with strategically idiotic moves.
But Google claimed that it had no APM advantage, and Google would never lie, right?
An Analysis On How Deepmind’s Starcraft 2 AI’s Superhuman Speed is Probably a Band-Aid Fix For The Limitations of Imitation Learning

Superhuman speed? Inability to learn? Oh my, that’s not what Google promised me.
I will try to make a convincing argument for the following:
-
AlphaStar played with superhuman speed and precision.
-
Deepmind claimed to have restricted the AI from performing actions that would be physically impossible to a human. They have not succeeded in this and most likely are aware of it.
-
The reason why AlphaStar is performing at superhuman speeds is most likely due to its inability to unlearn the human players’ tendency to spam click. I suspect Deepmind wanted to restrict it to a more human-like performance but they are simply not able to. It’s going to take us some time to work our way to this point but it is the whole reason why I’m writing this so I ask you to have patience.

The next part of his article somewhat retreads the ground I have already covered earlier. Although I do have to repost this juicy quote.
(((David Silver))), the Co-Lead of the AlphaStar team: “AlphaStar can’t react faster than a human player can, nor can it execute more actions, clicks per minute than a human player”.

Skipping ahead we get to the important bits.
The Starcraft 2 scene was dominated in 2018 by a player called Serral. This guy is fast. Maybe the fastest player in the world.
At no point is Serral able to sustain more than 500 APM for long. There is a burst of 800 APM but it only lasts a fraction of a second and is most likely resulted from spam clicking, which I will be discussing shortly.
But, but, a super intelligent AI overlord of the future would never do something as silly and humanlike as spam clicking, right? Also, didn’t we just see that TLO, another human, had APM peaks in excess of 2,000?
While arguably the fastest human player is able to sustain an impressive 500 APM, AlphaStar had bursts going up to 1500+. These inhuman 1000+ APM bursts sometimes lasted for 5-second stretches and were full of meaningful actions. 1500 actions in a minute translate to 25 actions a second. This is physically impossible for a human to do. I also want you to take into account that in a game of Starcraft 5 seconds is a long time, especially at the very beginning of a big battle. If the superhuman execution during the first 5 seconds gives the AI an upper hand it will win the engagement by a large margin because of the snowball effect.
Starcraft is a game with exponential power growth, in multiple ways. First, as you collect more resources, you can build more workers, to collect more resources faster, and so on and so forth. But since you are collecting more resources faster, the time between building a new worker shortens, so your rate of increase is itself increasing.
When it comes to battles the same is true. Let’s say we have team A, with 10 units, and team B, with 9 units, all of them marines. Team A will absolutely destroy team B. This is because all 10 units of team A will focus fire the first unit on the other side. Team B will do the same, but with only 9 units. As a result, the first unit of Team B will fall faster, which gives team A a temporary 10:8 firepower advantage. This won’t last long, because Team A will soon lose its first unit, but then Team B will lose the second unit even faster in comparison with Team A’s second unit, and so on. The end result will be that Team A has 4 marines remaining, while Team B gets wiped.
While this is true for numerical advantage, a similar advantage can be obtained by micro-managing the units. For instance, you notice that your marine is going to die, so you pull him to the backline and they have to target someone else. Micro gets incredibly complicated, and is mostly a dexterity check for human players. What Alphastar was doing was insanely precise inhumanely quick micro to get massive advantages in even, or even seriously worse encounters, and then using that to snowball the rest of the fight.
AlphaStar is able to sustain a 1000+ APM over a period of 5 seconds. Another engagement in game 4 had bursts going up to a dizzying 1500+ APM:
But we still have TLO and his 2,000+ APM bursts right? Well you’ll notice that while MaNa has a normal distribution of APM, TLO has this incredibly long tail. We’ll get to the quirk of Starcraft 2 to explain that, but understand that even MaNa’s APM is an illusion.
Most human players have a tendency to spam click. Spam clicks are exactly what they sound like. Meaningless clicks that don’t have an effect on anything. For example, a human player might be moving his army and curiously enough, when they click to where they want the army to go, they click more than once. What effect does this have? Nothing. The army won’t walk any faster. A single click would have done the job just as well. Why do they do it then? There are two reasons:
- Spam clicking is the natural by-product of a human being trying to click around as fast as possible.
- It helps to warm up finger muscles.
Remember the player Serral we talked about earlier? The impressive thing about him is actually not how fast he is clicking but how precise he is. Not only does Serral posses a really high APM (the total clicks per minute, including spam clicks) but also a ridiculously high effective-APM (the total clicks per minute, excluding spam clicks). I will be abbreviating effective-APM as EPM from this point onwards. The important thing to remember is that EPM only counts meaningful actions.
Serral’s EPM of 344 is practically unheard of. It is so high that to this day I still have a hard time believing it to be true. The differentiation between APM and EPM has some implications for AlphaStar as well. If AlphaStar can potentially play without spam, wouldn’t this mean that its peak EPM could be at times equal to its peak APM? This makes the 1000+ spikes even more inhuman. When we also take into consideration that AlphaStar plays with perfect accuracy its mechanical capabilities seem downright absurd. It always clicks exactly where it intends to. Humans misclick. AlphaStar might not play with its foot on the gas pedal all the time but when it truly matters, it can execute 4 times faster than the fastest player in the world, with accuracy that the human pro can only dream of.
He explains that the best human players typically only have about 200 EPM. The rest is garbage, with TLO being an extreme example that we’ll get to later. In contrast, Alphastar manages to have bursts of 1,500 EPM. Let me go and find that (((David Silver))) quote again.
“AlphaStar can’t react faster than a human player can, nor can it execute more actions, clicks per minute than a human player”.

BTW, the EPM of the human players also includes mistakes. So they could click a unit and move it accidentally when they were trying to attack the enemy. Or they click the unit to move, but since they would have needed to move the mouse across the screen, they don’t optimally position it, instead doing effective but sub-optimal movement.
There is a clear, almost unanimous consensus among the Starcraft 2 scene that AlphaStar performed sequences that no human could ever hope to replicate. It was faster and more precise than what is physically possible. The most mechanically impressive human pro in the world is several times slower. The accuracy can’t even be compared.
David Silver’s claim that AlphaStar can only perform actions that a human player is able to replicate is simply not true.

In this article he quotes from MaNa’s experience with playing alphastar.
MaNa: I would say that clearly the best aspect of its game is the unit control. In all of the games when we had a similar unit count, AlphaStar came victorious. The worst aspect from the few games that we were able to play was its stubbornness to tech up. It was so convinced to win with basic units that it barely made anything else and eventually in the exhibition match that did not work out. There weren’t many crucial decision making moments so I would say its mechanics were the reason for victory.
Translation: It’s dumb, but it micromanages the units really well so it wins.
There’s almost unanimous consensus among Starcraft fans that AlphaStar won almost purely because of its superhuman speed, reaction times and accuracy. The pros who played against it seem to agree. There was a member of the Deepmind team who played against AlphaStar before they let the pros test it. Most likely he would agree with the assessment as well. David Silver and Oriol Vinyals keep repeating the mantra of how AlphaStar is only able to do things that a human could do as well, but as we have already seen, that is simply not true.
Something about this is really sketchy.

Something about this is really jewy.
Aleksi does have some interesting speculation for what went wrong, and it serves as a great example of crushing the neural net hype.
Here’s what I suspect happened:
This is pure speculation on my part and I don’t claim to know for sure this happened. At the very start of the project, Deepmind agrees upon heavy APM restrictions on AlphaStar. At this point, the AI is not allowed to have superhuman bursts of speed we saw in the demonstration. If I was designing these restrictions they would probably look something like this:
- Maximum average APM over the span of a whole game.
- Maximum burst APM over a short period of time. I think capping it around 4–6 clicks per second would be reasonable. Remember Serral and his 344 EPM that was head and shoulders above his competitors? That is less than 6 clicks per second. The version of AlphaStar that played against Mana was able to perform 25 clicks per second over sustained periods of time. This is so much faster than even the fastest spam clicks a human can do that I don’t think the original restrictions allowed for it.
- Minimum time between clicks. Even if the speed bursts of the bot were capped, it could still perform almost instantaneous actions at some point during the time slice it was currently occupying and still perform in an inhuman way. A human being obviously could not do this.
Some people would argue for adding a random element on accuracy as well but I suspect that it would hinder the rate of training progress way too much.
All of this sounds super reasonable. I would probably have gone even further in the other direction. Limit the neural net to something like 1 action per second, or 60 per minute. Interestingly the DeepMind team states that they did something similar later in this piece.
Next Deepmind downloads thousands of high-ranking amateur games and begins imitation learning. At this stage, the agent is simply trying to imitate what humans do in games. The agent adopts a behavior of spam clicking. This is highly likely because human players spam click so much during games. It is almost certainly the single most repeated pattern of action that humans perform and thus would very likely root itself very deeply into the behavior of the agent.
This is what I mean when I say that these neural net AIs are retarded, and utterly lacking in context. Even the dumbest person on the planet would know not to waste APM doing garbage spam clicks. But since the neural nets don’t have any real intellect or understanding, it’s simply input output for them, and they couldn’t unlearn the spam clicking behaviour. It’s sort of like the walking behaviour we see in the first video in this piece. It can’t unlearn the bad habits.
What leaves the sourest taste in my mouth is this image:
It seems to be designed to mislead people unfamiliar with Starcraft 2. It seems to be designed to portray the APM of AlphaStar as reasonable. I don’t want to imply malicious intent, but even in the best case scenario, the graph is made extremely carelessly.
I’ll do that for you. That graph is designed maliciously to imply performance from alphastar that has no relationship to reality. The people who made that graph were aware of how misleading it was, and while it is technically true, it’s deceiving.
Now take a look at TLO’s APM. The tail goes up to and over 2000. Think about that for a second. How is that even possible? It is made possible by a trick called rapid fire. TLO is not clicking super fast. He is holding down a button and the game is registering this as 2000 APM. The only thing you can do with rapid fire is to spam a spell. That’s it. TLO just over-uses it for some reason. The neat little effect this has is that TLO’s APM’s upper tail is masking AlphaStars burst APM and making it look reasonable to people who are not familiar with Starcraft.
Deepmind’s blog post makes no attempt at explaining TLO’s absurd numbers. If they don’t explain TLO’s funky numbers they should not include them in the graph. Period.
This is getting dangerously close to lying through statistics. Deepmind has to be held to a higher standard than this.
Let me translate that for you. TLO’s “APM,” is just him holding down a button. A button that does nothing unless that particular ability is off cooldown, which will only be true for a single frame maybe once every few seconds. For some reason, Starcraft 2 counts that as a unique action each frame, for every single unit that he’s controlling. If he has 10 units, at 30 FPS, that’s 300 APS, or 18,000 APM. So the graph is dishonest in another way, because they don’t actually show the highest APM achieved by TLO. You can see that they cut it off arbitrarily at 2,000, and never explain his highest APM, because it would probably be so high that even non-Starcraft players would know something was up.
So now that it’s established that Alphastar only beats human players by being a cheating whore using computer micro-management of units, is there any valid strategy that it uses?
Komincz loaded two powerful Immortal units into a transport ship called a Warp Prism and flew them into the back of AlphaStar’s base, where fragile probes were gathering the minerals that power AlphaStar’s war machine. He dropped the Immortals into the base and began blasting away at the probes.
Komincz then repeated the gambit: drop the Immortals, destroy a couple of probes, then pick the Immortals up again just before the Stalkers arrive. He did it again. And again. As he did this, AlphaStar’s Stalker army wasted precious seconds marching back and forth indecisively.
“This is what I’m used to seeing when humans battle AIs,” Stemkoski said, as Komincz dropped the Immortals in AlphaStar’s base for the third time. “You’re finding something that they’re doing that’s a mistake and you’re making them do it over, and over, and over.”
There was another fairly mediocre pro player who destroyed alphastar in the very first exhibition doing something similar. Google won’t talk about him either, since his strategy was laughably simple. He just put some “undefended” units out where the AI got baited into attacking them. Then he had siege tanks waiting behind to blow them to bits. And then he did that over and over and over again getting free kills on alphastar.
I’m not saying that neural nets aren’t really cool. I’m not saying that they don’t have valid niches or things they can be good at. What I am saying is that people should be wary of insanely overhyped bullshit tech garbage.










Let’s also take a second to recognize that while TLO and MaNa are really good at Starcraft 2, they’re not Clem. They’re not Serral. They’re not Reynor. They’re not Maru. They’re not Parting. They’re not Life. etc.
They’re not even close.
Those guys would lazily assrape Alphastar every single game with growing resentment that their time was being wasted.
Serral also lost to alphastar.
That’s shocking. Build order loss or something?
Or just a bajillion apm type thing?
He lost multiple games. He wasn’t on his keyboard, and made lots of mistakes, but mostly it’s because the AI is a cheating whore.
This is terrific. I’ve been curious about machine learning and AI, and sort of assumed it was shitty but had been hyped like it wasn’t. Video games are a nice display of its capabilities because there are so many possibilities for success and failure. Quite a good series you’re writing.
Back in my day we just played vidya to have fun. Now everyone fucking mixmaxes everything, every vidya game, to the point that even having a normal time for the average casual player is a waste of time (unless you play 24/7) and even further now we have retarded AI (the concept is retarded) trying to beat human players, so some nerds in a tech company can claim the ultimate minmax. Its fake, gay, and ruining the gaming community.