

Remember Francesca Gino? She was the Harvard behavioural psychologist who did lots of research on honesty. She was exposed for rampant fraud and placed on academic leave, although she is now suing Harvard for defamation.

“What’s wrong with fudging a little data?” -Francesca Gino, probably
We also recently saw Mark Tessier-Lavigne resign from his post as Stanford President, due to rampant fraud conducted under his watch. At least in his case the research wasn’t about honesty, but rather biology.

Marc Tessier-Lavigne
But today it’s Deja Jew, as Dan Ariely, an Israeli-American behavioural economist and pop-sci writer, has been caught with, you guessed it, rampant fraud in his research into honesty. This story is absurdly similar to the Gino Francesca story, and it turns out that they even collaborated on at least one paper together.
Data Colada first caught Ariely back in 2021, and wrote a followup just last month. However, this is the first I’ve heard of it, so let’s go to the 2021 expose to find out how Mr. Ariely sinned.
In 2012, Shu, Mazar, Gino, Ariely, and Bazerman published a three-study paper in PNAS (.htm) reporting that dishonesty can be reduced by asking people to sign a statement of honest intent before providing information (i.e., at the top of a document) rather than after providing information (i.e., at the bottom of a document). In 2020, Kristal, Whillans, and the five original authors published a follow-up in PNAS entitled, “Signing at the beginning versus at the end does not decrease dishonesty” (.htm). They reported six studies that failed to replicate the two original lab studies, including one attempt at a direct replication and five attempts at conceptual replications.
First I should mention that Dan Ariely suffered a burn to the right side of his body as an eighteen year old in the Israeli Offense Force when a magnesium flare went off beside him. This is responsible for his somewhat offputting look. I don’t care how unusual people look, and I won’t be focusing on this, but I felt that I needed to mention this at some point because it is somewhat of an elephant in the room.

Anyway, the honesty paper was fraudulent, which is why it failed to replicate. The hypothesis is also pretty bizarre, which is why they had to fake data to “prove” it. No one would really expect that signing an honesty pledge would matter much, and whether this pledge is located at the top or bottom of the page would probably matter even less. If anything, seeing an honesty pledge would make me think that I would be more likely to get away with lying, since they need to beg me not to do it.
Turns out our intuition was right, and the hypothesis is bunk. I’ll cover this a later, but so much of Ariely’s “behavioural economics,” is Malcolm Gladwell-tier JustSo stories about unintuitive truths that are actually just false. In the case of the first study they found him faking data on, the JustSo story was that people are more honest when asked to sign an honesty pledge before doing a task.
Our focus here is on Study 3 in the 2012 paper, a field experiment (N = 13,488) conducted by an auto insurance company in the southeastern United States under the supervision of the fourth author. Customers were asked to report the current odometer reading of up to four cars covered by their policy. They were randomly assigned to sign a statement indicating, “I promise that the information I am providing is true” either at the top or bottom of the form. Customers assigned to the ‘sign-at-the-top’ condition reported driving 2,400 more miles (10.3%) than those assigned to the ‘sign-at-the-bottom’ condition.
…
On to the anomalies.
Let’s first think about what the distribution of miles driven should look like. If there were about a year separating the Time 1 and Time 2 mileages, we might expect something like the figure below, taken from the UK Department of Transportation (.pdf) based on similar data (two consecutive odometer readings) collected in 2010 [2]:
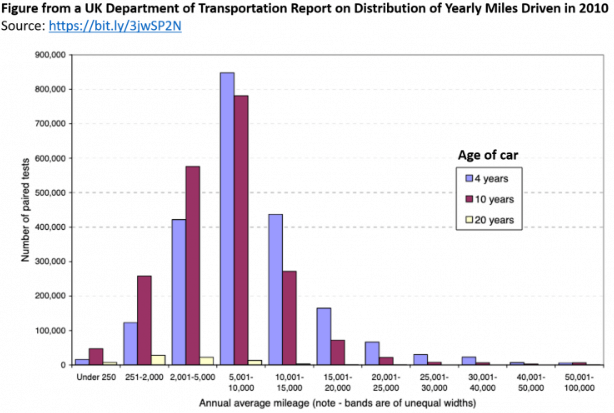
As we might expect, we see that some people drive a whole lot, some people drive very little, and most people drive a moderate amount.
As noted by the authors of the 2012 paper, it is unknown how much time elapsed between the baseline period (Time 1) and their experiment (Time 2), and it was reportedly different for different customers [3]. For some customers the “miles driven” measure may reflect a 2-year period, while for others it may be considerably more or less than that [4]. It is therefore hard to know what the distribution of miles driven should look like in those data. It is not hard, however, to know what it should not look like. It should not look like this:
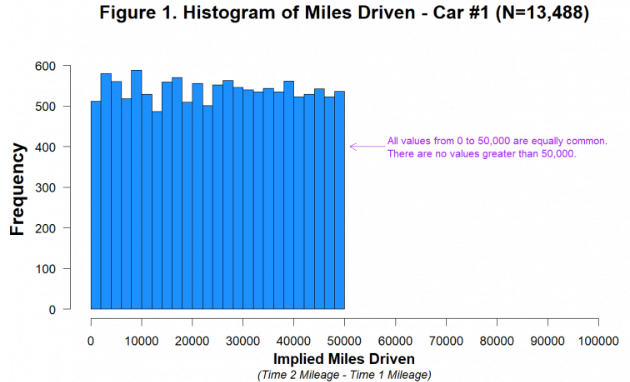
This histogram shows miles driven for the first car in the dataset. There are two important features of this distribution.
First, it is visually and statistically (p=.84) indistinguishable from a uniform distribution ranging from 0 miles to 50,000 miles [5]. Think about what that means. Between Time 1 and Time 2, just as many people drove 40,000 miles as drove 20,000 as drove 10,000 as drove 1,000 as drove 500 miles, etc. [6]. This is not what real data look like, and we can’t think of a plausible benign explanation for it.
Second, you can also see that the miles driven data abruptly end at 50,000 miles. There are 1,313 customers who drove 40,000-45,000 miles, 1,339 customers who drove 45,000-50,000 miles, and zero customers who drove more than 50,000 miles. This is not because the data were winsorized[extreme values eliminated] at or near 50,000. The highest value in the dataset is 49,997, and it appears only once. The drop-off near 50,000 miles only makes sense if cars that were driven more than 50,000 miles between Time 2 and Time 1 were either never in this dataset or were excluded from it, either by the company or the authors. We think this is very unlikely [7].
A more likely explanation is that miles driven was generated, at least in part, by adding a uniformly distributed random number, capped at 50,000 miles, to the baseline mileage of each customer (and each car). This is easy to do in Excel (e.g., using RANDBETWEEN(0,50000)).
In summary, the first problem with the data is that Ariely somehow managed to not get a normal distribution of mileage, but a uniform distribution. I’m sure most of my readers understand how absurd that is, but let me give a hypothetical example to put this into perspective.
Imagine that I’m doing a study, ostensibly to help already grown adults grow even taller through my amazing supplement snake oil. Since I’m a huckster, I never conduct the study, and just fake it. At the end of a year we compare the heights of the test subjects. What we should see is a normal distribution, where a huge percentage of the people are within an inch of average, then a smaller percentage are about three inches from average, then a tiny percentage are, say, six inches above or below average, etcetera. Below is an approximation of what we should see.
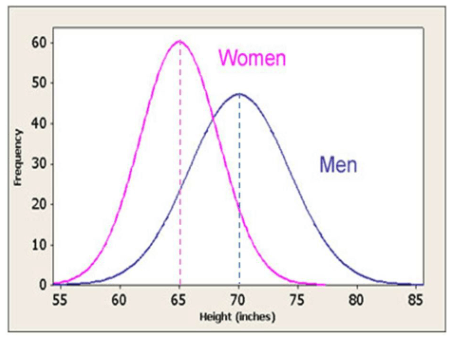
But when I created this fake data I accidentally forgot to create a normal distribution, and instead just created a uniform distribution. What this means is that seven foot tall monsters are equally as common in my collection of imaginary test subjects as six feet tall men.

Likewise, these little gremlins are also just as common.

Unless the sample size is ten and consists entirely of an NBA team and Anal First, I doubt this could happen. If you have a large and unbiased sample size, you’re going to get a normal distribution of height. If you have over 13k samples in your car insurance study, as Ariely had, there is no excuse for a distribution like this.
The mileages reported in this experiment were just that: reported. They are what people wrote down on a piece of paper. And when real people report large numbers by hand, they tend to round them. Of course, in this case some customers may have looked at their odometer and reported exactly what it displayed. But undoubtedly many would have ballparked it and reported a round number. In fact, as we are about to show you, in the baseline (Time 1) data, there are lots of rounded values.
But random number generators don’t round. And so if, as we suspect, the experimental (Time 2) data were generated with the aid of a random number generator (like RANDBETWEEN(0,50000)), the Time 2 mileage data would not be rounded.
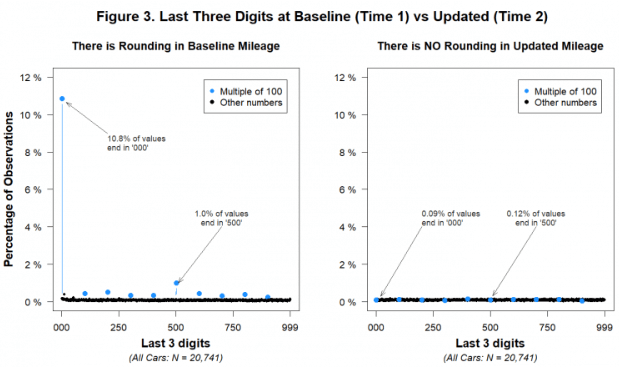
The figure shows that while multiples of 1,000 and 100 were disproportionately common in the Time 1 data, they weren’t more common than other numbers in the Time 2 data. Let’s consider what this implies. It implies that thousands of human beings who hand-reported their mileage data to the insurance company engaged in no rounding whatsoever. For example, it implies that a customer was equally likely to report an odometer reading of 17,498 miles as to report a reading of 17,500. This is not only at odds with common knowledge about how people report large numbers, but also with the Time 1 data on file at the insurance company.
You can also see this if we focus just on the last digit:
The second problem with the data is that it is actually too random.
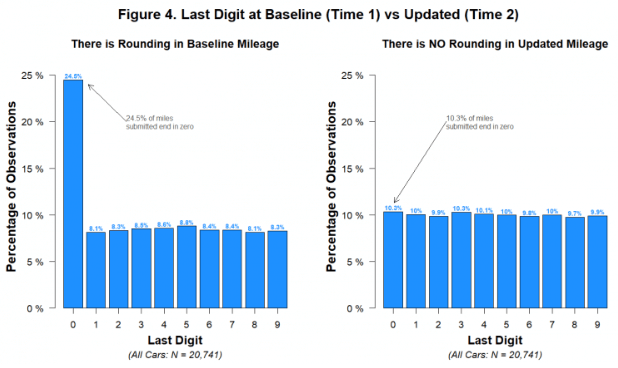
When people give their odometer readings, a very high percentage of them, roughly 25%, will give you a reading that ends with 0. We would expect that only 10% of them have odometer readings that actually end in zero, so the only explanation, especially with a sample size in the tens of thousands, is rounding. Similarly, a disproportionally high amount of them will give a number that is a multiple of 100 or 1000.
This is what we see with the first numbers supplied by the insurance company. The second batch, that Ariely obviously faked, doesn’t show any of this rounding. For us to believe this study, we would need to believe that the exact same 13k+ people all simultaneously stopped rounding their odometer readings when sending the data to the insurance company. There is no reason to believe this, and Ariely never comments on it, despite it ostensibly being the most interesting part of the study.

“Then this one time, everyone stopped rounding their odometers for no reason, and turns out mileage doesn’t follow a normal distrubition. Crazy!”
Just like Francesca Gino, Dan Ariely is a pathetic fraud who didn’t bother putting in the small amount of work required to make his fraud believable. If he had simply created reasonable fake data, which is not particularly difficult, no one could have figured out that his study was fake. That is one of the key takeaways from this recent bout of academic fraud. They only got caught because they were astonishingly sloppy. A somewhat bright seventh grade kid could have done a better job matching the fake data with the real data, but Dan Ariely is a genius behavioural economist, so he just types RANDBETWEEN(0,50000) in Excel and calls it a day.
With that, another genius hypothesis of his is proven. More than a decade later it becomes slowly debunked after ten more experiments fail to find the effect. In the meantime, he’s got more books to sell, Governments to work with – and get paid handsomely by – and TED Talks to bloviate at. Speaking of which, here’s one of at least three that I found on YouTube.
Ariely has another unintuitive truth (that is actually wrong) that he’s bloviating about. His idea is that people like things more when they have to put work into them. This is obviously true in some unique situations such as athletic achievement. Here he goes full retard, and generalizes niche phenomenon to cake baking.
10:40
The fact that I have to build [my IKEA furniture], does that create a particular attachment between me and my furniture? We call this the IKEA affect, and some evidence for this exists from cake mixes.
So when cake mixes came out in the fifties, to the surprise of the people who made up the cake mixes they were not very popular, and the question is why? Pie crusts were popular, cookies were popular, and all kinds of other ready mixes were popular, but not cakes.
I’ll point out that he quantifies absolutely none of this, despite the data supposedly being out there.
And one of the theories was that maybe people did not have to do much for these cakes. Maybe if you take a mix and you pour it into some thing – add some water, put it into the oven and then make it and somebody says “what a great cake,” you just can’t feel good about it.

Yes, it really is this stupid. People like cakes more when they have to work harder to eat them.
So maybe it was the fact that it didn’t require as much work that made the cake mixes not as appealing. This was known as the “egg theory,” and what they did to test it was they took the eggs out of the cake mix.

It’s physically painful for me to sit through such nonsense.
All of a sudden the cake mix was the same, you just had to add some eggs and some milk to it. What happened now was that cake mixes became much more popular. Somehow, having to put work into something make[sic] it more appealing.
*Audience of dipshits chuckles*
Wow, that’s such an unintuitive truth! I bet that the reason why it’s so unintuitive is definitely not because it’s entirely baseless.

Ariely blitzes through this in about thirty seconds, before flitting off to the next bit of dipshittery. He doesn’t appear to consider this a big deal. It’s just yet another unintuitive little truth that he’s found out and is happy to share with you, but let’s take a minute to actually consider the enormity of the argument.
He is explicitly saying that people have the option of buying two different cake mixes that make equally tasty cakes. The only difference is that one requires more effort – more money as well although he doesn’t mention this – for absolutely no improvement in taste, texture, or anything else. Naturally, everybody goes for the high effort cake mix.

I don’t know what’s a stronger claim. That people like doing work for no reason, or that adding fresh eggs and fresh milk to a cake mix doesn’t make it taste better than a cake mix with weird powderized egg and milk product already mixed in.

I consider myself a fairly decent amateur chef. So much so that I’ve overshared some of my home recipes on this site before.

Utterly delicious chicken, mushroom, and pepper risotto.
But you don’t need to have ever cooked anything before to understand that adding fresh ingredients makes things tastier. To argue otherwise is to make such an astonishing claim that it borders on revolutionary. But Dan “fake data” Ariely just blithely moves on. He’s the genius here. He can’t be bothered with little things like “facts and logic.”
There’s a widely believed myth that boxed cake mixes sold poorly until companies decided to require the addition of an egg. Rumor has it that the American housewives of the ‘30s and ‘40s felt guilty about contributing next to nothing to the baking process. They’d been taught that homemade is always best, and just adding water to powder was an insufficient amount of work.
That may have been true for some bakers, but that’s probably not why General Mills decided to go the egg route in the 1950s.
The fact is, adding eggs produces a superior cake.
Proteins in the egg help provide the cake’s structure, while the fats in the yolk make it richer and keep the texture becoming chewy. The yolk also contains emulsifiers that help the ingredients blend together smoothly.
Holy cow! Adding fresh eggs to cake mix makes it taste better, according to literally everyone who has the slightest clue what they’re talking about, but not Dan Ariely.

Turns out the unintuitive truth that people like doing lots more work to make the same cake was just wrong. People like doing the least amount of work when cooking. The reason they add fresh eggs and fresh milk to cake mixes is because it makes them taste better and for no other reason. We do not need to come up with some sort of psychological explanation for this. Cakes need eggs, cake mixes without eggs added are trash, conversation over.

This reminds me of Malcolm Gladwell, and his claim that it literally does not matter where a quarterback is drafted in the NFL, since they are all equally good. These snarky midwits absolutely love their unintuitive truths that are obviously wrong, almost as much as they love their One Weird Anecdote That Proves A Bizarre Theory That Is Actually Just Not True Either. Another group in this category is the traffic antifas. Go read my work on Induced Demand if you haven’t already.
0:55
But what about reasons for good? And I’ll tell you about a study we did, and the experiment worked like this. We give people a six sided die and we say “why don’t you throw the die, and we’ll pay you whatever it comes up. It comes up six you get six dollars, five you get five, and so on. But, you can get paid based on the top side or the bottom side. Top or bottom you decide, but don’t tell us.”
So I give you the die I say “don’t tell me, think top or bottom now toss the die.” And let’s say the die comes with five on the bottom and two on the top. And now I say “what did you pick?” Now if you picked bottom you say bottom you get five dollars. But if you picked top what do you say? Do you say the truth, top? Or do you change your mind you say bottom and you get five dollars?
In our experiment people do this twenty times, and every time they think top or bottom, commit it to memory, toss the die and they write 5 and 2, they say “I picked 5,” and so on. When you do this twenty times you find that people are… extra lucky. And luck has this really nice feature of focusing on the six-one die tosses. They’re extra lucky on the six-one die tosses, not so much on the three-four.

Ariely does a really crappy job of explaining his own study. Here’s a better explanation.
For instance, a die might land with 5 on the bottom and 2 on top. Ariely asked the participant who rolled the die, “Which side did you pick?” If the participant had picked “bottom,” no problem, but if they had picked “top,” they faced a dilemma — should they lie to make more money or tell the truth and make less money?
If the die lands with six up, then one is on the bottom, five up, two is on the bottom, four up, three is on the bottom, and all of those in reverse for when the other side of the pair is up. So when one is up, six is on the bottom, etcetera.
We continue with Ariely.
Now here’s the thing, we do the same experiment, but we connect people to a lie detector. We ask the question of whether the lie detector can detect it. The answer is yes, the lie detector can detect lies. Not all the time, but it can detect.
In another version of the experiment we do the same thing, but people pick a charity. And all the money they are going to make today goes to a charity, a good cause. What do you think happens, people cheat more or less? People cheat more and the lie detector stops working.
Why? Because what does the lie detector detect? The lie detector detects tension. “I want more money but I think it’s wrong.” But if it’s not wrong, why would you worry? If it’s for a good cause you can still think of yourself as a good person.
This is another one of those studies that works if you assume that the test subjects are a bunch of autistic retards. It stops working the second that you imagine yourself as the test subject.

So you’re a college student, and you’ve been told that you can make money for your charity of choice by rolling well. You’ve been hooked up to a lie detector machine, and there’s a bunch of faggots looking at you and collecting notes. Then you roll the die, and have the option to lie in order to secure more cash for your charity.
Apparently, what every single person feels in that moment is absolutely no inhibitions against lying, so they lie constantly and without remorse.

Is that how you would react? Are you sure that you wouldn’t lie zero percent of the time, just to fuck with the experimenter? What about lying in the opposite direction? I know that if I ever found myself in one of these morons studies I would do everything in my power to figure out what result they wanted and then give them the exact opposite.
People don’t behave the same when they know that they’re part of a study. Even if we trust the data for the study, which Ariely doesn’t provide, there are alternative hypotheses that could easily explain this behaviour.
Also, the whole thing about the lie detector not working anymore is way too cute to be true. I personally would feel more nervous lying on behalf of a charity, since I would care more about getting away with it. His pithy quote of “if it’s not wrong, why would you worry?” is astonishingly stupid if you think about it for more than a second.

Joseph Stalin was pretty evil. Therefore, if it was 1920’s in the Soviet Union, you wouldn’t feel nervous about leading a coup trying to overthrow him, right? You’re not doing anything wrong, so there’s no reason to be worried according to this fake genius. That’s definitely the only time when people are worried, is when they personally feel like they’re doing something wrong. Oh and when people think that they’re lying on behalf of a charity, they instantly stop being worried even though they’re hooked up to a lie detector machine and there are experimenters watching them like hawks.

Also, what if they don’t believe that the money is going to a charity? There are innumerable reasons why this is a junk study, and these are objections that I came up with off the top of my head.
Everything that Dan Ariely does is this JustSo neatly wrapped up bullshit that doesn’t come close to capturing the complexity of real human psychology. The above video is all about how easy it is to manipulate people by pretending that something is free. The top observer accidentally makes a far deeper and more real insight than Ariely.
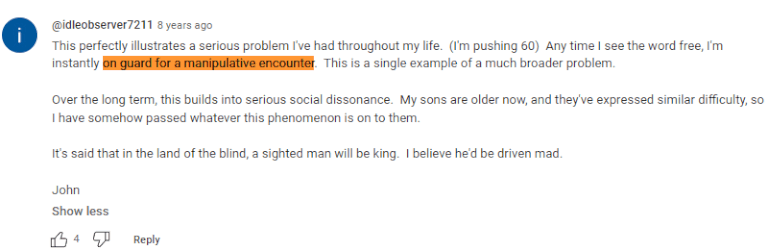
This perfectly illustrates a serious problem I’ve had throughout my life. (I’m pushing 60) Any time I see the word free, I’m instantly on guard for a manipulative encounter. This is a single example of a much broader problem.
It’s almost like people aren’t abject morons, and don’t like being manipulated into doing things that aren’t in their interest. 99% of the pop-psychology that you can find on the internet about “one weird trick to never be unmotivated,” or “how to get everyone to love you,” is total nonsense that doesn’t work. Dan Ariely, Malcolm Gladwell, Francesca Gino, and all the rest of these frauds are like the psychology/behavioural economics version of the PUA fags, who pretended that you could get hawt wahmens to suck your dick by working “below me,” into the conversation.

Provided you weren’t DMVing the HB9 two set with your cocky funny routines of course.

Dan Ariely and Francesca Gino only got in trouble for the data that they faked, yet there is the much more serious crisis of everything they do being bullshit where the alternative hypothesis is often far more natural and plausible than their idiotic interpretations of the data.
As mentioned earlier, it’s true that cake mixes got more popular when the producers started asking the customers to add fresh eggs and fresh milk. Ariely blithely concludes that this is because people enjoy doing work for no reason. Everyone who knows what they’re talking about says it’s because cake mixes with fresh eggs and milk added taste far superior. We would need a further double blind study to determine whether people enjoy the cake mixes with eggs added, except that actually we don’t because it is so obviously true that cake mixes with fresh eggs and milk taste better that it’s not worth our time. 
In this case the alternative hypothesis isn’t even a small little objection that we need to attend to, it’s obviously the correct interpretation of reality. Any serious scientist would have catalogued all the possible interpretations of the data/study beforehand. Ariely didn’t, because he’s a fraud. This never-ending refusal to consider the alternative hypothesis is a far bigger and more damning scandal in modern pseudo-intellectualism, and it’s also almost never talked about.
The most respected social scientists are willing to go with batshit crazy interpretations of data, and even make up fraudulent data, for studies about random apolitical pet theories of theirs. Keep that in mind when you see some “study” that proves that Da Blax are horribly oppressed in some way. One of the simplest versions is the idea that Jequeeruses of Colour are overrepresented in prison because of Aryan Supremacists making up crimes, instead of Blacks just committing more crimes.
Narrator: So far, we have talked about theoretical models that Ariely presented, not about investments. But in 2018, Ariely offered the Israeli public to invest in a special fund called the Dan Ariely model. Many were impressed and invested in the fund more than 100 million shekels.
You saw the results of the fund. What were the results in the end?
Professor: Ariely’s fund did not manage to break the index. In fact, it achieved lower rates for investors. For example, people who invested in his index were supposed to get a higher rate of return. On the contrary, the investors in his fund were exposed to more risk and received a lower rate.
…
Professor: The budget department thought it needed some serious behavioral economist that could provide some insights. And it turned to Dan Ariely because Dan Ariely is a very, very well-known and out-going person in this field.
Narrator: According to the data that we examined, Dan Ariely’s budget for the Finance Ministry was 17 million shekels in four years. Is that a lot?
[NOTE: It’s a little more than 4 million USD, as of time of writing.]
Professor: That’s a lot. In general, a very large amount. In general, consulting companies do not take amounts that are close to this amount. 17.5 million shekels in this context is a huge amount.
Narrator: In other words, this is an amount that buys a serious amount of work.
Professor: A very, very massive and very large amount of work that you need to hear about.
Dan Ariely is such a scammer that he even scams his fellow Israelis. When doing research I thought I stumbled upon a video featuring Dan Ariely from “Kikenomics.” I was missing an l, but it weirdly fits.
Anyway, that’s modern psychology/behavioural economics for you.
I’ve heard people say that social science is incapable of proving anything but the blindingly obvious. Outside of IQ research – although that is also quite obvious – I’ve yet to see any evidence contrary.













I don’t care what anybody says, that Francesca Gino has got to be a jew. and as for gladwell, don’t worry, he’s got jamaican ancestry! JFC…
“I was innocently trying to burn down a palestinians house and i burnt my face. “
Ted talks are as jewy as it gets. The Ted scam is simply the evolution of the kike American info-mercial, dressed up with pseudo intellectual bullshit. Anyone who pays attention to Ted tards is a certified fucking idiot. This shitty little tribe of jew rodent shysters just cannot help themselves. They desperately need to be helped by benevolent outsiders with a steel will.
Jew should shave the other side of his face so that he can tell bald-face lies.
[…] AcademiaLand: Another Honesty Researcher, (((Dan Arielly))), Exposed for Rampant Fraud […]
Demand characteristics strike again.
Nothing else needs to be said, really.